爆竹声中一岁除,春风送暖入屠苏。 在新春烟火声中,DeepSeek也如绚烂的烟火,悄然点亮了AI领域的上空。
成本低,性能强...DeepSeek以一己之力告诉世人:大模型的训练成本也许可以不用那么高。
日出东方
2025年1月27日,英伟达股价单日暴跌16.86% ,市值蒸发近6000亿美元,创下美股单日最大跌幅纪录。
 英伟达股价出现剧烈波动
英伟达股价出现剧烈波动
究其根本,是中国企业DeepSeek在1月20日推出的新开源推理模型R1。
 DeepSeek官网[1]
DeepSeek官网[1]
这款新模型不仅在性能上与OpenAI的o1相当,并且在训练环节采用的创新方法也极大降低了对高端GPU需求以及对英伟达CUDA生态的依赖。
 DeepSeek-R1的基准性能测试[2]
DeepSeek-R1的基准性能测试[2]
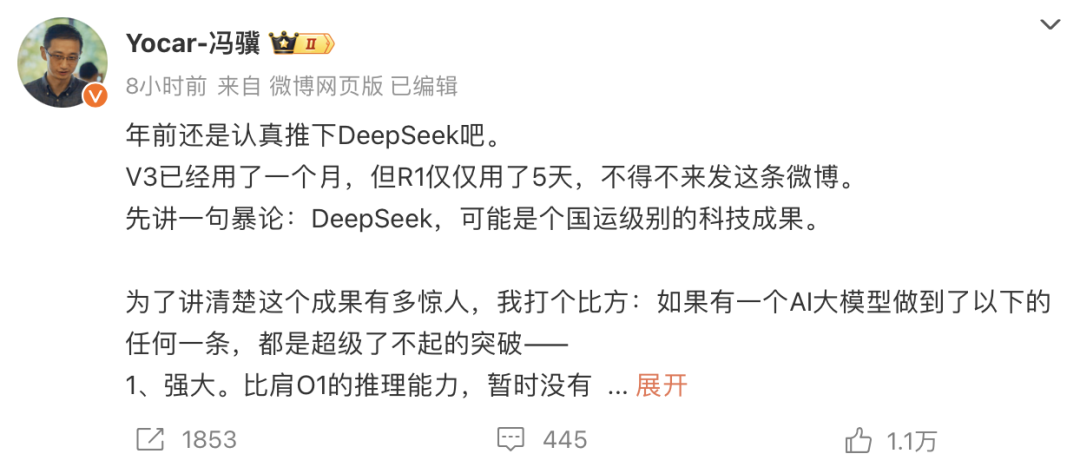
游戏科学创始人、黑神话悟空制作人冯骥在微博上称:DeepSeek,可能是个国运级别的科技成果。
那么DeepSeek究竟做了哪些创新,又是如何让众人直呼“Amazing”的呢?
深度求索
尽管DeepSeek-R1是在2025年1月发布,但早在2024年12月26日时,DeepSeek已经发布了新一代大模型:DeepSeek-V3。在V3的技术报告中详细记录了:如何让大模型训练更有性价比。
 DeepSeek-V3技术报告[3]
DeepSeek-V3技术报告[3]
混合专家模型(MoE)
我们在过往接触到的相当一部分大模型,都是一种 密集型模型(Dense Model) 。如果将大模型想象为一个人脑,那么这相当于每次要做一件事时,无论是跑步还是写论文,大脑的所有区域都会被激活。
 神经网络示例
神经网络示例
但本次DeepSeek所采用的混合专家(Mixture of Experts)模型,与实际人脑的运作形式更加接近:每次行动,都只有少部分脑区会被激活,这样就极大地减少了能量的消耗。
 DeepSeekMoE
DeepSeekMoE
根据专家的看法[4],通过这样的训练方式,能在 减少大约30% 的计算资源情况下,获得相同的模型性能。
在实际训练中,DeepSeek还增加了一个 辅助无损失负载平衡 以平衡MoE训练与模型最终性能[5]。
多头潜在注意力(MLA)
DeepSeek-V3通过采用 多头潜在注意力 节省了大量运算和推理的内存,使得R1[6]节省了约 80%-90% 的内存开销[7],也因此R1的推理成本仅为O1的27分之一[8]
 DeepSeek定价
DeepSeek定价
面对这样的“价格战”,OpenAI首先坐不住了,Sam Altman紧急调整了ChatGPT定价和服务策略。

有分析人员指出OpenAI当初如此之高的定价,必然意味着其拥有巨大的利润空间,用以补贴其在训练层面的巨额投入:
OpenAI赚了非常多的钱,因为他们是唯一具备这种能力的公司。
深入硬件:PTX
真正撼动英伟达股价的则是技术报告中的另一条消息:
Specifically, we employ customized PTX instructions and auto-tune the communication chunk size. —— P.14
受制于GPU禁运的影响,中国企业无法直接获取高性能的GPU,而为了提高训练的效率,DeepSeek必须在有限的条件下,尽可能挖掘现有GPU的全部性能。
 绿点为中国企业可获取的GPU类型
绿点为中国企业可获取的GPU类型
从现有的报告来看,他们也许在CUDA层或者更接近硬件的层次进行了超底层编程,结合以上所有,最终催生出了那令人叹为观止的训练成本:
 依照DeepSeek估算,本次V3训练仅需557万美元
依照DeepSeek估算,本次V3训练仅需557万美元
余波未了
当国外越来越多的大模型企业,以安全为理由,逐渐走向闭源,以性能为目标,逐渐扩大开销。我们突然发现:原来前往AGI的路上不只有“关门大力出奇迹”。
 基于类似R1蒸馏方式,李飞飞团队以不到50美元训练了S1模型
基于类似R1蒸馏方式,李飞飞团队以不到50美元训练了S1模型
在模型火爆全球后,DeepSeek也遭受了更猛烈的网络攻击:
 攻击来源的IP地址主要来自于美国
攻击来源的IP地址主要来自于美国
根据2月6日消息,DeepSeek目前已经暂停了API服务充值,官方给出的解释是:“服务器资源紧张”。
 充值按钮为灰色不可用
充值按钮为灰色不可用
尽管DeepSeek还有很多有意思的细节,但在最后,小R向各位分享一句DeepSeek创始人梁文峰在一年前接受采访时的话:务必要疯狂地怀抱雄心,且还要疯狂地真诚。也许那时的人们还会担心他们的命运:要如何抵御来自OpenAI或者Google的风暴。
一年后的今天,随着越来越多的厂商接入DeepSeek模型,也许这群坚持开源、突破算力限制的勇士们,会向风暴低语:我们就是风暴。